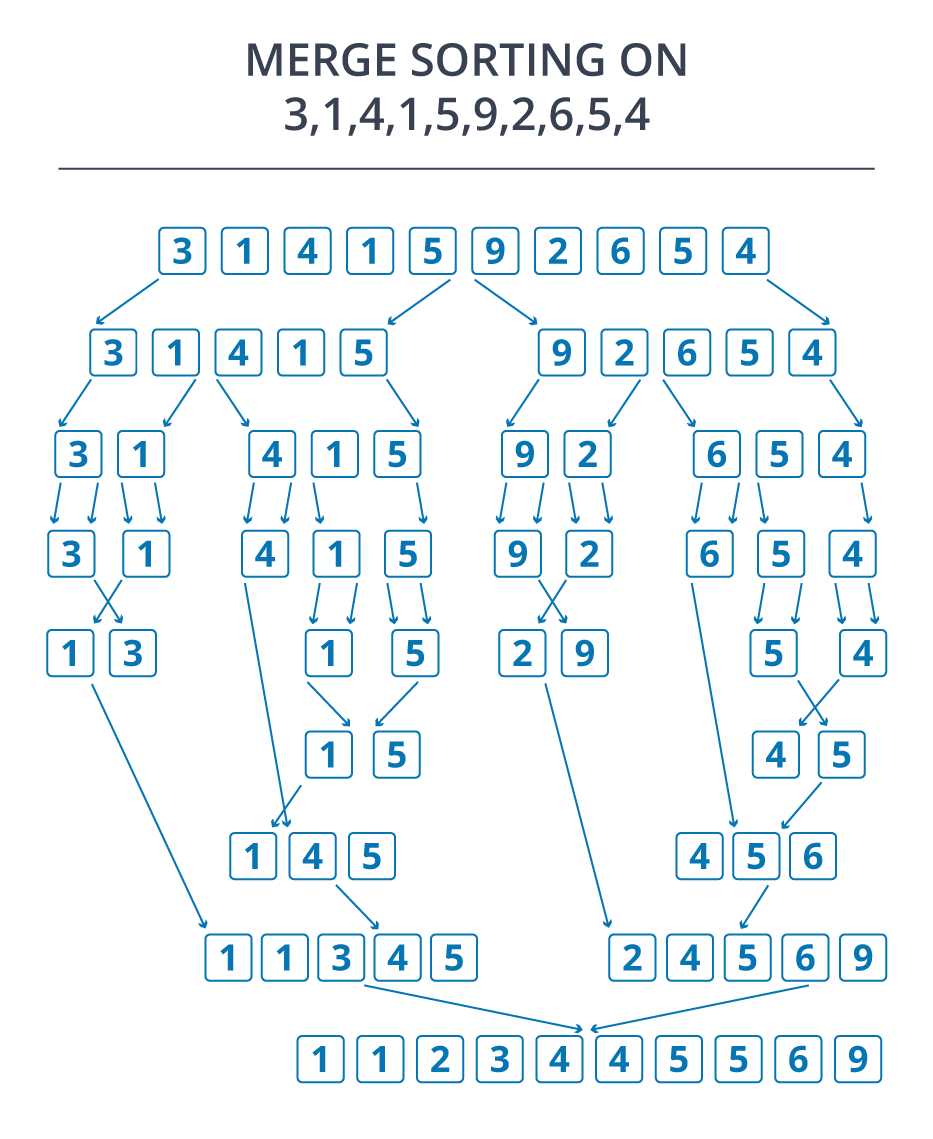
Responsabilidades do administrador do Hadoop
Este blog sobre as responsabilidades do administrador do Hadoop discute o escopo da administração do Hadoop. Os trabalhos de administrador do Hadoop estão em alta demanda, então aprenda o Hadoop agora!

Este blog sobre as responsabilidades do administrador do Hadoop discute o escopo da administração do Hadoop. Os trabalhos de administrador do Hadoop estão em alta demanda, então aprenda o Hadoop agora!
O Apache Spark surgiu como um grande desenvolvimento no processamento de big data.
O Apache Hadoop 2.x consiste em melhorias significativas em relação ao Hadoop 1.x. Este blog fala sobre Hadoop 2.0 Cluster Architecture Federation e seus componentes.
Isso dá uma ideia do uso do rastreador de trabalho
O Apache Pig possui várias funções predefinidas. O post contém etapas claras para criar UDF no Apache Pig. Aqui, os códigos são escritos em Java e requer a Biblioteca Pig
A arquitetura do HBase Storage compreende vários componentes. Vamos examinar as funções desses componentes e saber como os dados estão sendo gravados.
Apache Hive é um pacote de armazenamento de dados construído sobre o Hadoop e é usado para análise de dados. O Hive é voltado para usuários que se sentem confortáveis com SQL.
A implementação do Apache Spark com Hadoop em grande escala pelas principais empresas indica seu sucesso e seu potencial quando se trata de processamento em tempo real.
O NameNode High Availability é um dos recursos mais importantes do Hadoop 2.0 NameNode High Availability com o Quorum Journal Manager é usado para compartilhar logs de edição entre os NameNodes ativos e em espera.
As responsabilidades do trabalho do desenvolvedor Hadoop cobrem muitas tarefas. As responsabilidades do trabalho dependem do seu domínio / setor. Essa função é semelhante a um desenvolvedor de software
Os modelos de dados do Hive contêm os seguintes componentes, como bancos de dados, tabelas, partições e intervalos ou clusters. O Hive oferece suporte a tipos primitivos como inteiros, flutuantes, duplos e strings.
Esses 4 motivos para atualizar para o Hadoop 2.0 falam sobre o mercado de trabalho do Hadoop e como ele pode ajudá-lo a acelerar sua carreira, tornando-o aberto a grandes oportunidades de trabalho.
Neste blog, vamos executar exemplos de Hive e Yarn no Spark. Em primeiro lugar, crie Hive e Yarn no Spark e depois execute exemplos de Hive e Yarn no Spark.
O objetivo deste blog é aprender como transferir dados de bancos de dados SQL para HDFS, como transferir dados de bancos de dados SQL para bancos de dados NoSQL.
O Cloudera Certified Developer para Apache Hadoop (CCDH) é um impulso para a carreira de alguém. Esta postagem discute os benefícios, padrões de exame, guia de estudo e referências úteis.
Este blog fornece uma visão geral da arquitetura de alta disponibilidade HDFS e como instalar e configurar um cluster de alta disponibilidade HDFS em etapas simples.
Apache Kafka continua a ser popular quando se trata de análise em tempo real. Aqui está uma visão do ponto de vista de carreira, discutindo oportunidades de carreira e demandas de emprego.
O Apache Kafka fornece sistemas de mensagens escaláveis e de alto rendimento, tornando-o popular em análises em tempo real. Aprenda como um tutorial Apache kafka pode ajudá-lo
Esta postagem do blog é um mergulho profundo no Pig e suas funções. Você encontrará uma demonstração de como trabalhar no Hadoop usando Pig sem dependência de Java.
Este blog discute os pré-requisitos para aprender Hadoop, fundamentos de Java para Hadoop e respostas 'você precisa de Java para aprender Hadoop' se você conhece Pig, Hive, HDFS.