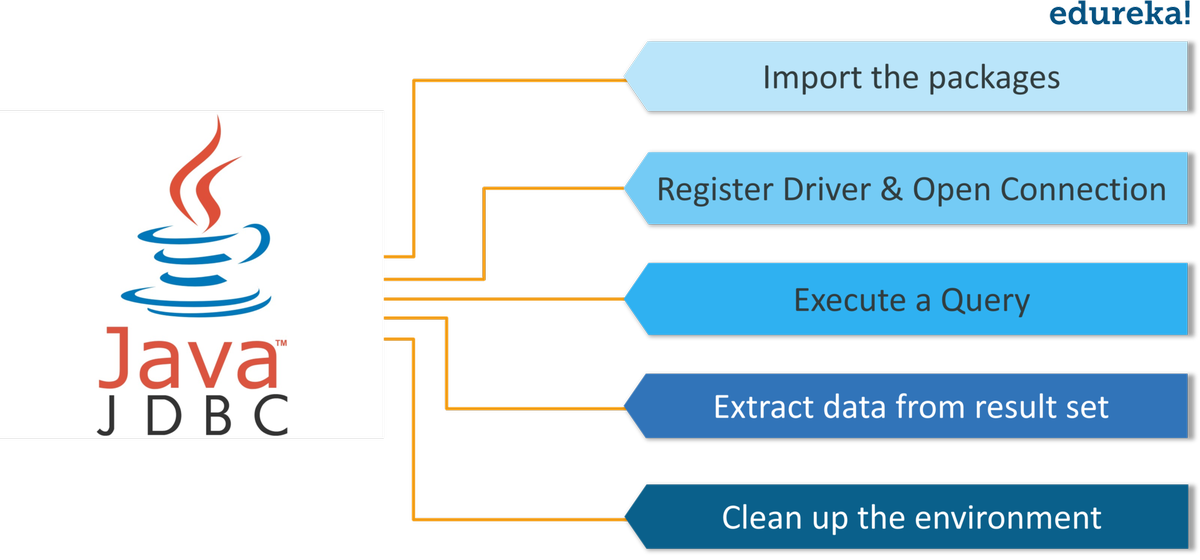
Spark vs Hadoop: qual é a melhor estrutura de Big Data?
Esta postagem do blog fala sobre apache spark vs hadoop. Isso lhe dará uma ideia sobre qual é a estrutura de Big Data certa para escolher em diferentes cenários.

Esta postagem do blog fala sobre apache spark vs hadoop. Isso lhe dará uma ideia sobre qual é a estrutura de Big Data certa para escolher em diferentes cenários.
Este blog ajuda a entender como instalar e configurar o plug-in sbteclipse com instruções passo a passo para executar o aplicativo Scala no Eclipse IDE.
Esta postagem do blog explica por que você deve começar a usar o Apache Spark após o Hadoop e por que aprender o Spark depois de dominar o hadoop pode fazer maravilhas pela sua carreira!
Este tutorial do Apache Drill fornece todas as informações de que você precisa para começar a usar o mecanismo de consulta Apache Drill, uso com Hadoop, Big Data e Apache Spark.
Este blog do Spark Hadoop conta tudo o que você precisa saber sobre o Apache Spark combineByKey. Encontre a pontuação média por aluno usando o método combineByKey.
Apache Falcon é uma nova plataforma de gerenciamento de dados para o ecossistema Hadoop que simplifica o processamento de feed de integração e gerenciamento de feed em clusters de hadoop. Aprenda como configurá-lo.
Este blog do Apache Spark explica os acumuladores Spark em detalhes. Aprenda o uso do acumulador Spark com exemplos. Os acumuladores de faísca são como contadores Hadoop Mapreduce.
Saiba tudo sobre o Apache Flink e a configuração de um cluster Flink neste blog. Flink suporta processamento em lote e em tempo real e é uma tecnologia de Big Data obrigatória para Big Data Analytics.
Esta postagem do blog discute o cache distribuído com variáveis de transmissão e apresenta uma introdução à distribuição eficiente de grandes valores na programação do Spark.
As certificações CCA e CCP da Cloudera substituíram os exames CCDH e CCSHB. Este blog contém tudo o que você precisa saber sobre as novas certificações.
Esta postagem de blog discute as transformações com estado com janelas no Spark Streaming. Aprenda tudo sobre como rastrear dados em lotes usando D-Streams de última geração.
Esta postagem do blog discute transformações com estado no Spark Streaming. Saiba tudo sobre o rastreamento cumulativo e o aprimoramento de habilidades para uma carreira no Hadoop Spark.
As tecnologias Hadoop e Big Data estão revolucionando a análise de saúde. Este blog de big data em saúde discute como a análise de big data pode melhorar o atendimento médico.
Esta postagem do blog sobre Hadoop Streaming é um guia passo a passo para aprender a escrever um programa Hadoop MapReduce em Python para processar enormes quantidades de Big Data.
Este blog no Tutorial de Big Data oferece uma visão geral completa de Big Data, suas características, aplicações e também desafios com Big Data.
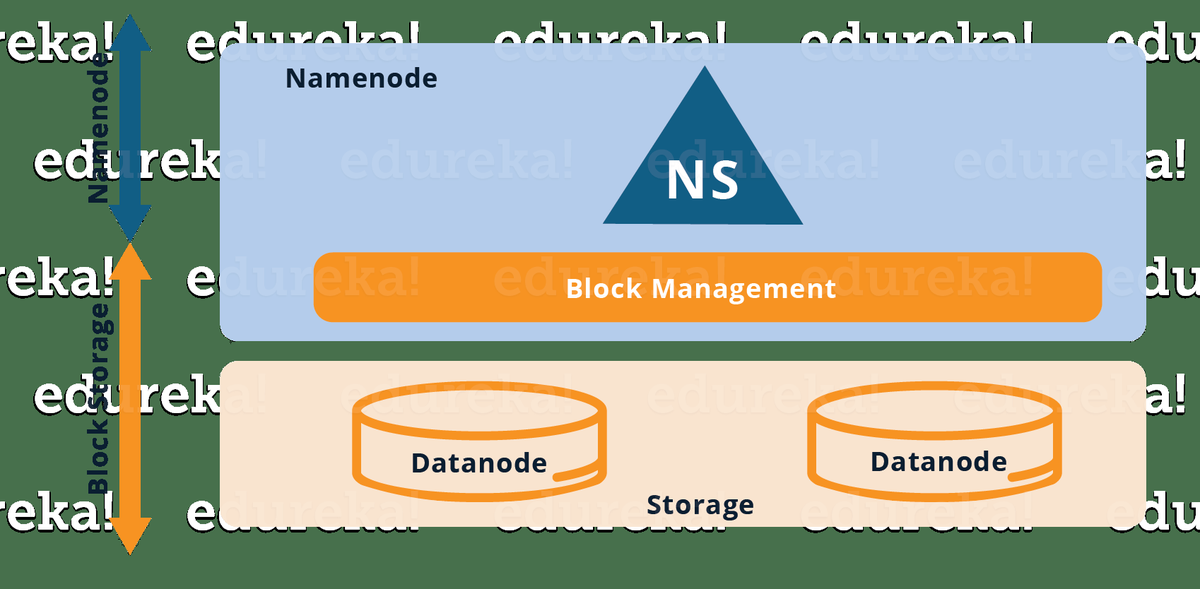
Este blog do tutorial do HDFS ajudará você a entender o HDFS ou Hadoop Distributed File System e seus recursos. Você também explorará seus componentes principais resumidamente.
Neste tutorial do Splunk, entenda as diferenças entre Splunk vs. ELK vs. Sumo Logic e determine qual dessas ferramentas se adapta melhor a você.
Neste blog de caso de uso do Splunk, você entenderá como a Domino's Pizza usou o Splunk para obter insights sobre o comportamento do consumidor e formular suas estratégias de negócios.
Este tutorial é um guia passo a passo para instalar o cluster Hadoop e configurá-lo em um único nó. Todas as etapas de instalação do Hadoop são para a máquina CentOS.
Este blog fala sobre os vários comandos HDFS como fsck, copyFromLocal, expunge, cat etc. que são usados para gerenciar o sistema de arquivos Hadoop.