Tutorial do HBase: Introdução ao HBase e estudo de caso do Facebook
Este blog de tutorial do HBase apresenta o que é o HBase e seus recursos. Também cobre o estudo de caso do Facebook Messenger para entender os benefícios do HBase.

Este blog de tutorial do HBase apresenta o que é o HBase e seus recursos. Também cobre o estudo de caso do Facebook Messenger para entender os benefícios do HBase.
Este blog é um guia sobre como instalar o Puppet Master e o Puppet Agent. Também inclui um exemplo para implantar o Apache Tomcat usando o módulo Puppet Tomcat.
Este blog é um guia passo a passo para a instalação do Apache Pig em ambiente Linux. Vamos instalar o Apache Pig 0.16.0 e executá-lo em diferentes modos.
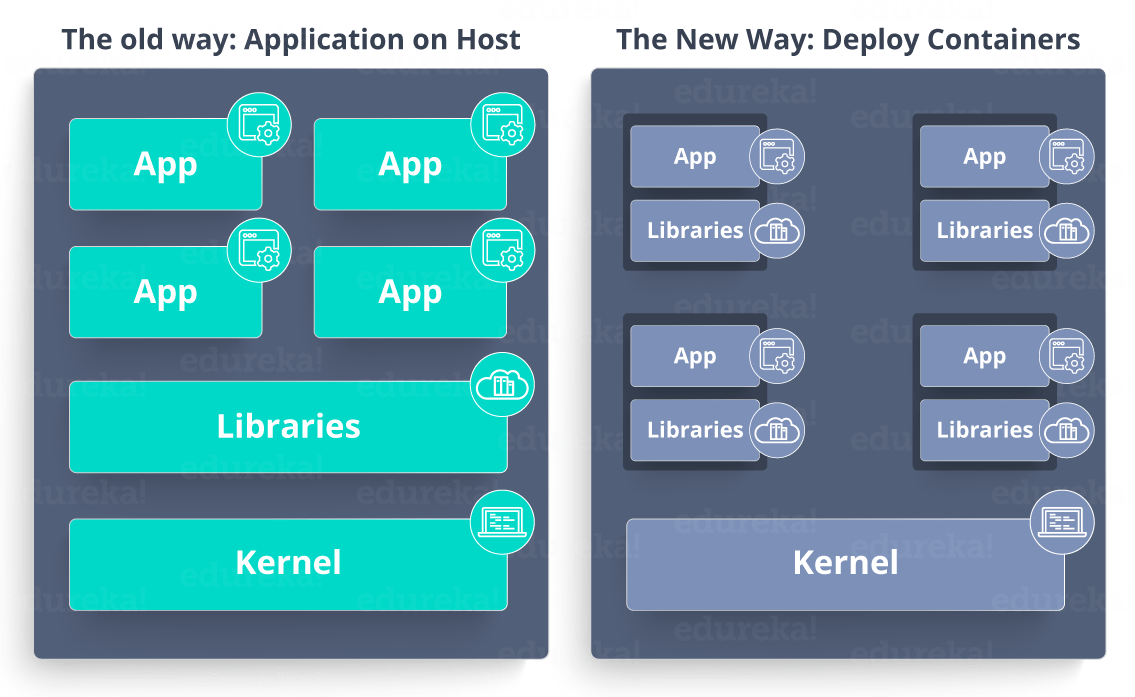
Este blog sobre Arquitetura HBase explica o Modelo de Dados HBase e fornece uma visão da Arquitetura HBase. Também explica os diferentes mecanismos do HBase.
Este blog de tutorial do Hive oferece um conhecimento profundo da arquitetura do Hive e do modelo de dados do Hive. Também explica o estudo de caso da NASA sobre o Apache Hive.
Este blog do Spark Streaming apresentará o Spark Streaming, seus recursos e componentes. Inclui um projeto de análise de sentimento usando o Twitter.
Este blog do Spark MLlib apresentará a biblioteca de aprendizado de máquina do Apache Spark. Inclui um projeto de Sistema de recomendação de filmes usando Spark MLlib.
Este blog do tutorial do GraphX apresentará o Apache Spark GraphX, seus recursos e componentes, incluindo um projeto de análise de dados de voo.
Este blog de tutorial do Apache Flume explica os fundamentos do Apache Flume e seus recursos. Ele também exibirá o streaming do Twitter usando o Apache Flume.
Tutorial do Apache Sqoop: Sqoop é uma ferramenta para transferência de dados entre Hadoop e bancos de dados relacionais. Este blog cobre importação e exportação Sooop do MySQL.
Tutorial do Apache Oozie: Oozie é um sistema de agendador de fluxo de trabalho para gerenciar trabalhos do Hadoop. É um sistema escalonável, confiável e extensível.
Os aplicativos de Big Data estão revolucionando as organizações e ajudando-as a tomar decisões de negócios mais informativas ao analisar grandes volumes de dados.
O Apache Spark assumiu o controle do mundo do Big Data & Analytics e Python é uma das linguagens de programação mais acessíveis usadas na indústria hoje. Então, aqui neste blog, aprenderemos sobre Pyspark (faísca com python) para obter o melhor dos dois mundos.
Este blog se concentra no Apache Hadoop YARN, que foi introduzido no Hadoop versão 2.0 para gerenciamento de recursos e agendamento de tarefas. Explica a arquitetura YARN com seus componentes e as funções desempenhadas por cada um deles. Ele descreve o envio do aplicativo e o fluxo de trabalho no Apache Hadoop YARN.
Neste blog no Tutorial do PySpark, você aprenderá sobre a API PSpark que é usada para trabalhar com o Apache Spark usando a linguagem de programação Python.
Neste blog de tutorial do PySpark Dataframe, você aprenderá sobre transformações e ações no Apache Spark com vários exemplos.
Este blog da Edureka no Tutorial do Cloudera Hadoop lhe dará uma visão completa dos diferentes componentes do Cloudera como Cloudera Manager, Parcels, Hue etc
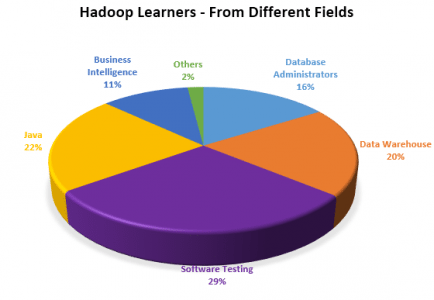
Esta postagem descreve sobre o aumento na demanda de habilidades de Hadoop e NoSQL na TI e em outros campos. continue lendo para ver como as habilidades de Hadoop e NoSQL ajudarão
Este blog discute as vantagens da implementação do Hadoop, iniciativas do Hadoop, Hadoop em pequenas e grandes organizações e benefícios de carreira do treinamento do Hadoop.
O Hadoop se tornou uma habilidade importante a ser adquirida no circuito de TI, o número de perfis de alunos de Hadoop está aumentando drasticamente dia a dia.